Policymakers frequently assume that when an intervention was found effective in one setting, the same results can be repeated elsewhere. However, the history of social programs is replete with examples of programs that, while effective in one location, simply failed to work elsewhere. The federal government has a poor record of replicating effective social programs.[REF] Examples include the Center for Employment Training (CET) replication,[REF] the Head Start CARES Demonstration,[REF] and Hawaii’s Opportunity Probation with Enforcement (HOPE) program.[REF]
A more recent example is the federal government’s Teen Pregnancy Prevention (TPP) grants, created by the Consolidated Appropriations Act of 2010.[REF] TPP grants are administered by the Office of Adolescent Health (OAH) within the Department of Health and Human Services (HHS). The OAH “invests in the implementation of evidence-based TPP programs, and provides funding to develop and evaluate new and innovative approaches to prevent teen pregnancy.”[REF]
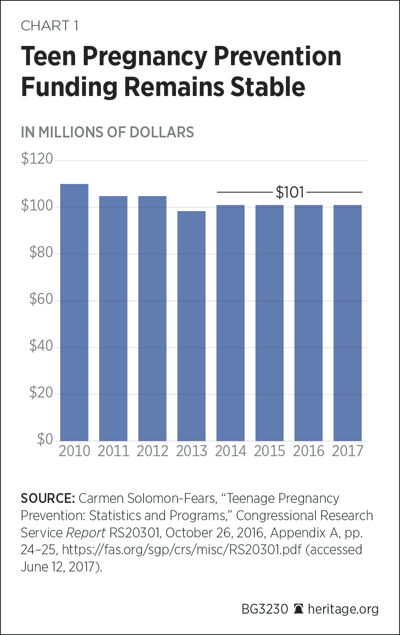
Funded with approximately $100 million per fiscal year (FY) since its inception, the TPP is supposed to award “competitive contracts and grants to public and private entities to fund medically accurate and age appropriate programs that reduce teen pregnancy.”[REF] Chart 1 provides the amount of funding for TPP from FY 2010 to FY 2017. To date, Congress has spent more than $820 million on TPP.[REF]
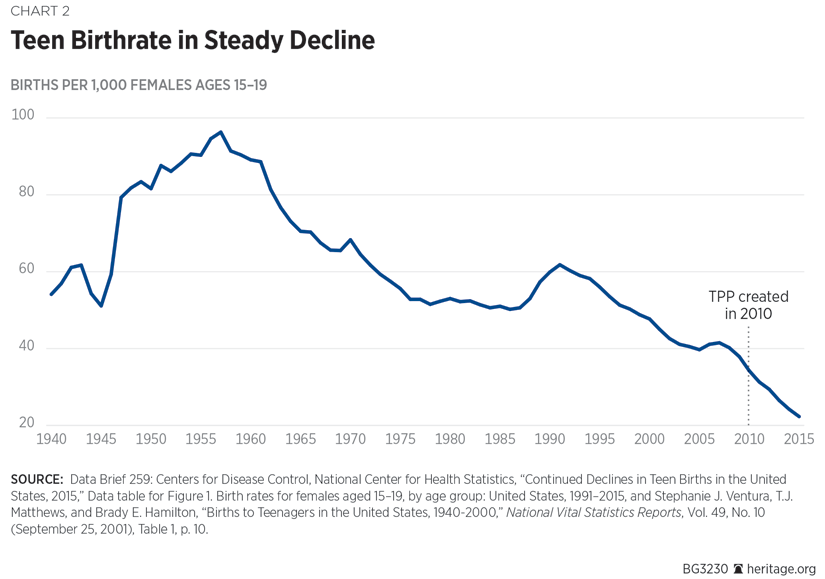
As shown in Chart 2, the trend in births to girls between 15 years and 19 years of age has steadily declined for decades. Commenting on the decline in the teen birth rates since the implementation of TPP in 2010, Results for America—an evidence-based-policy advocacy group—concluded, without any evidence: “While it is not realistic to associate all the success to TPP alone, it has contributed significantly to the use of proven approaches to reduce teen pregnancy.”[REF] Similarly, a TPP-funded supporter, Associate Professor Christine Dehlendorf of the University of California, San Francisco, recently wrote:
Teen birth rates have been declining since the 1990s. New data reveal an even sharper drop in the five years following the inception of the TPP program, from about 34 births per 1,000 girls in 2010 to 22 per 1,000 in 2015—a 35 percent decrease. This unprecedented decline suggests that the Office of Adolescent Health’s funding strategy for teen pregnancy prevention has been highly effective.[REF]
Readily apparent in Chart 2 is the fact that the beginning of the decline in teen births began decades before the creation of TPP. Advocates of evidence-based policymaking should be above confusing correlation with causation.
In other cases, proponents of TPP causally assert that the program is effective while conveniently ignoring the actual, publicly available, evaluations that conclusively demonstrate the program’s ineffectiveness. For example, Robert Gordon, the acting Deputy Director of the Office of Management and Budget during the Obama Administration, recently criticized the Trump Administration’s plan to cut funding for the program. Gordon concluded that TPP “works” and that President Trump’s “decision to terminate the program was based on ideology rather than evidence.”[REF]
The statements by Results for America, Associate Professor Dehlendorf, and Gordon raise a significant flaw in the nearly automatic assumption by the evidence-based-policy community that the replications of program models labeled “evidence-based” are effective. Advocates of evidence-based policymaking, especially those in Washington, DC, pay little regard to the difficulty of replicating program models. As Amy Feldman Farb and Amy Margolis of the OAH wisely caution, “Programs that were effective at one point in time, particularly decades ago, may no longer be effective today, nor in new settings and populations of young people.”[REF] In addition, the quality of the staff replicating the program may not be the same as that of the original staff. A particularly good instructor may have certain “intangibles” that influence participant outcomes far more than the faithful implementation of the curriculum. This conclusion is highly relevant to the evaluation literature used to identify program models labeled “evidence-based” and, thus, qualified for federal funding.
Teen Pregnancy Prevention Grants
TPP has two funding streams: Tier I and Tier II grants. According to HHS, Tier I grants are awarded to grantees replicating programs that “have been shown, in at least one program evaluation, to have a positive impact on preventing teen pregnancies, sexually transmitted infections, or sexual risk behaviors.”[REF] Thus, Tier I grants are supposed to be “evidence-based.” The majority of TPP funding is dedicated to “effective program models” funded by the Tier I grants.[REF] The other set of TPP grants, Tier II, fund demonstration programs that do not meet the OAH’s evidence-based definition, but are considered by the OAH to be innovative programs worthy of funding.
In June 2016, Ron Haskins, a research fellow at the Brookings Institution and co-chair of the Commission on Evidence-Based Policymaking, testified before Congress that HHS requires “high-quality evidence showing that the programs produced significant impacts on important measures of teen sexual activity or teen pregnancy for the TPP program.”[REF] According to Results for America, the “tiered-evidence framework enables more dollars to be directed towards programs that have demonstrated success and are ready to be scaled for wider impact, while also directing lesser amounts of funding toward interventions that need to be tested and proven.”[REF] Further, Results for American claims that “Tier 1 grants support the replication of evidence-based programs that are proven to reduce teenage pregnancy or related risk behaviors.”[REF] (Emphasis added.)
Results for America and others believe that these grants will be effective because they are replicating programs labeled “evidence-based.” Is this assumption correct? Ron Haskins wisely acknowledges that most of the TPP Tier I models “had been evaluated only once by rigorous methods, leaving open the question of whether they could be successfully replicated.”[REF] As will be discussed later, the evidence of effectiveness underlying the Tier I grants is not nearly as robust as evidence-based-policy advocates have claimed. Many of the reviewed evaluations are not rigorous at all. Further, the evaluations of the evidence-based replications overwhelmingly find failure. Yet, the evidence-based policymaking community is virtually silent on this failure.
Unlike many federal grants that award funding with little regard to ensure that grantees faithfully implement the intended programs, the OAH places high standards on reporting measures on grantees to ensure that the “evidence-based” models were administered as intended. These requirements are intended to ensure implementation fidelity—the degree to which programs follow the theory underpinning the program, and how correctly the program components are put into practice.
The evaluated TPP grants “were required to engage in a phased-in implementation period lasting up to one year to allow time for thorough needs assessments and partner development.”[REF] Further,
[i]mplementations were required to maintain fidelity to the program model and be of high quality as rated by an independent observer, high levels of youth retention and engagement were expected, and programs had to be medically accurate and age appropriate.[REF]
Performance measurement data was reported to the OAH every six months to ensure implementation fidelity.[REF]
Each of the Tier I grantees is supposed to evaluate the impact of the evidence-based model they are replicating. So far, from 2015 to May 2017, 13 experimental evaluations of nine “evidence-based” models have been published by HHS or in the American Journal of Public Health.[REF] This review of this literature focuses on the Tier I grants that have undergone randomized experiments to assess effectiveness. Overwhelmingly, these evaluations demonstrate that replicating “evidence-based” models to affect the sexual behaviors of participants fails to produce the intended results. Clearly, replicating an “evidenced-based” model does not guarantee similar results.
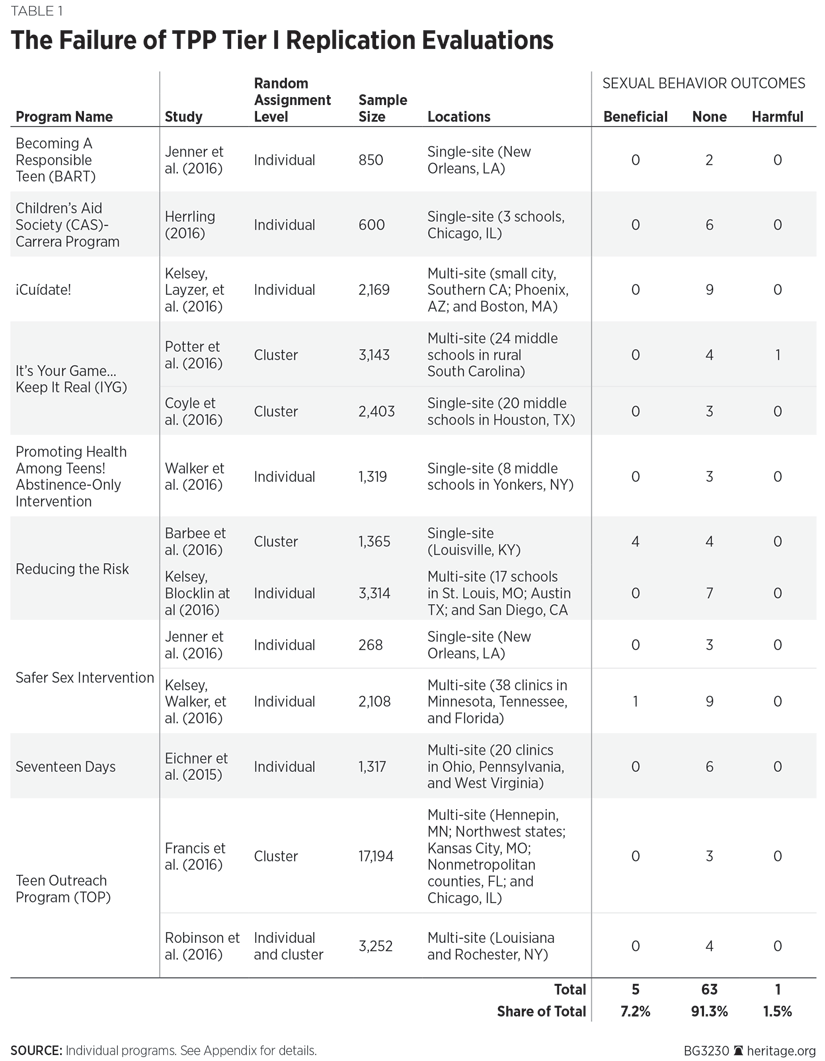
Table 1 summarizes the results of the TPP Tier I experimental replication evaluations. Due to their methodological weaknesses, quasi-experimental evaluations are excluded from Table 1. First, the level of random assignment is classified as individual or cluster. Experimental evaluations that use random assignment are the “gold standard” of evaluation designs.[REF] Randomized experiments attempt to demonstrate causality by holding constant all other possible causes of the outcome, isolating the program intervention as the only possible cause of differing outcomes, and observing whether the outcomes differ between the intervention and control groups. This methodology works best when the unit of analysis is randomly assigned to intervention and control groups. For the TPP I replication evaluations, the unit of analysis is the individual (for instance, student or youth).
However, a drawback to the scientific rigor of several TPP Tier I experimental evaluations is that while the unit of analysis is the individual, random assignment was, instead, based on clusters of individuals (such as schools and classrooms). Groups of students in classrooms or schools were randomly assigned to intervention and control groups. As will be seen from the literature review, several of these evaluations had intervention and control groups that were not equivalent on characteristics that can bias the results.[REF] Therefore, these cluster randomization evaluations do not provide results that are as definitive as evaluations that randomly assigned individuals to intervention and control groups.
Second, Table 1 provides the sample size for each of the evaluations. The benefits of random assignment are most likely to occur with large sample sizes. Randomized evaluations using small sample sizes do not have the same scientific rigor as randomized evaluations using large sample sizes. Random assignment helps to ensure that the control group is equivalent to the intervention group in composition, predisposition, and experience. The groups are composed of the same types of individuals in terms of program-related and outcome-related characteristics. In addition, members of both groups should be similarly disposed toward the program. Further, the intervention and control groups should have the same experiences regarding time-related variables, such as their maturity level and history.[REF]
Randomized experiments have the highest internal validity when sample sizes are large enough to ensure that idiosyncrasies that can affect outcomes are evenly distributed between the program and control groups. With small sample sizes, disparities in the program and control groups can influence the findings. For this reason, evaluations with large samples are more likely to yield scientifically valid impact estimates.
Third, Table 1 classifies the evaluations as single or multi-site evaluations. The evaluations are classified as single site if the study takes place in a single county, city, town, or school district. When the evaluations take place in more than one county, city, town, or school district, these studies are classified as multi-site evaluations. This means that evaluations that take place in several schools in a single school district, for example, are classified as single-site evaluations.
Large-scale experimental evaluations based on multiple sites avoid problems of simplistic generalizations. A multitude of confounding factors that vary by location can influence the performance of social programs.[REF] What works in Tulsa, Oklahoma, may not work in Baltimore, Maryland. Thus, the larger the size of the evaluation (for instance, the sample size and number of sites), the more likely the social program will be assessed under all of the conditions under which it operates. For TPP, the multi-site evaluations are an attempt to “scale-up” the OAH’s evidence-based models to determine if these models can be successful when applied in multiple settings. However, “[r]esearch across many fields has demonstrated that when programs are scaled up, as in effectiveness or replication studies, they often don’t find the same positive outcomes the original studies found.”[REF]
Fourth, Table 1 summarizes the results of the evaluations by classifying outcomes for sexual behaviors as “beneficial,” “no effect,” and “harmful.” A statistically significant impact where the intervention group fared better than the control group is classified as beneficial. For example, if the intervention group reports statistically lower rates of sexual activity than the rates reported by the control group, this outcome is considered beneficial. However, a statistically significant impact where the intervention group did worse than the control group is classified as harmful. A finding of no effect occurs when the difference in outcomes for the intervention and control groups is statistically indistinguishable—meaning that the intervention failed to influence the outcome being assessed in either a beneficial or harmful way.
As becomes immediately clear from Table 1, the replications of TPP Tier I “evidence-based” models overwhelmingly find failure. Of 69 main outcomes, 63 (91.3 percent) were statistically insignificant—meaning that these “evidence-based” replications had no meaningful effect on sexual behaviors. Only five (7.2 percent) of the main outcomes were found to have beneficial impacts that were statistically significant, while one (1.4 percent) outcome was a statistically significant harmful impact.
Commenting on the effectiveness of TTP, Russell Cole, a senior researcher at Mathematica Policy Research, understatedly wrote, “Despite these investments, many of the evaluations did not show favorable, statistically significant results on behavioral outcomes.”[REF] These results should not be surprising. The federal government does not have a successful track record of funding effective sex-education programs. For example, a multi-site experimental evaluation of abstinence-education programs found that this approach had no effect on the sexual activities of youth.[REF]
In addition to the low likelihood that programs that worked in one setting, would work in other circumstances, another reason for the failure of TPP may be the inconsistent and methodologically weak evidence used to label the program models as evidence-based. For example, the OAH used contradictory evidence of the effectiveness of Becoming A Responsible Teen (BART) program to label this model “evidence-based.” Of the three randomized experiments that were classified with a “high” ranking for scientific rigor, two found the model to be ineffective.[REF] Labeling BART an “evidence-based” model contradicts the body of research evaluating the program.
The results for the Tier II grants are similar to the failure of the Tier I grants. From 2015 to May 2017, the OAH has released 12 final reports based on experimental evaluations of Tier II grant programs.[REF] These evaluations overwhelmingly find that these programs fail to affect the sexual behavior outcomes.[REF]
A Review of the Evidence
The following sections review the evidence-based literature used by HHS to label specific models as evidence-based, and the results of the replications of these models through Tier I grants:[REF]
- Becoming A Responsible Teen (BART);
- Children’s Aid Society, Carrera Adolescent Pregnancy Prevention Program;
- ¡Cuídate!;
- It’s Your Game: Keep It Real (IYG);
- Promoting Health Among Teens! Abstinence-Only Intervention;
- Reducing the Risk;
- Safer Sex Intervention;
- Seventeen Days; and
- Teen Outreach Program (TOP).
The programs reviewed are limited to replications that have undergone experimental evaluations that have been released to the public. First, the original evaluations that the OAH reviewed to identify program models as “evidence-based” are described. “High” quality ratings are assigned to random assignment studies with attrition rates that were not considered problematic.[REF] Quasi-experimental studies received “moderate” quality ratings, along with random assignment studies with high attrition. Studies with ratings of “low” quality did not meet either of the high or moderate quality criteria. Second, the results of Tier I replication findings for each evidence-based model are presented.
Becoming A Responsible Teen (BART).
Prior Evaluations. The evidence-based classification used by the OAH for the BART model is based on five evaluations of “low” to “high” in scientific rigor that have inconsistent findings of success.[REF] The first evaluation, published in 1995, received a “high” quality rating by the OAH for its random assignment design.[REF] The small-scale evaluation assessed the effect of the eight-week education and behavioral skills program implemented in an after-school community-based setting that served black youth with an average age of 15.3 in an undisclosed Southern city with 400,000 residents.[REF] Self-reported sexual behavior was assessed during six-month and 12-month follow-ups. Averaged over the entire length of the follow-up period, the treatment group reported lower incidents of unprotected oral sex and anal intercourse, and higher incidents of condom-protected intercourse, than the control group.[REF]
Similar to the 1995 study, the 1999 study received a “high” rating for scientific rigor.[REF] This evaluation attempted to assess the effectiveness of BART applied to incarcerated males in a state reformatory in the Southern state.[REF] A total of 428 young men entering a juvenile correctional facility were randomly assigned to an intervention and control group. At the six-month follow-up after release from the facility, members of the intervention group fared no better or worse on all sexual outcomes assessed.[REF]
A 2002 study failed to use a control group and only assessed the before-and-after participation effect of BART on attitude and knowledge of the risks of sexual activity.[REF] Correctly, the OAH gave this study a “low” ranking for scientific rigor because of its weak scientific methodology and failure to assess behavioral changes.[REF] Similarly, the OAH classified a 2009 study as not meeting their review criteria.[REF] While this particular study used random assignment, the evaluators did not assess any outcomes related to actual changes in sexual behavior.[REF]
Last, a 2011 random assignment study, classified with a “high” ranking, assessed the effectiveness of BART when applied to incarcerated female youths.[REF] With an average follow-up of nine months post-release, the small-scale experiment found that the program had no effect on contraceptive use, the frequency of sexual intercourse while under the influence of alcohol or drugs, or acquiring sexually transmitted infections or HIV.[REF]
Thus, the majority (two out of three) of random assignment evaluations with high rankings of scientific rigor found BART to be ineffective. Despite more consistent evidence of failure than success, the OAH misleadingly labeled BART as an “evidence-based” model.
TPP Tier I Replication. The OAH funded an evaluation that attempted to replicate the inconsistent impacts of BART in a different setting.[REF] Performed by The Policy & Research Group, the evaluators randomly assigned 850 minority teens, ages 14 to 18, participating in a summer youth program in New Orleans, to a control group and an intervention group.[REF] As seen in Table 1, this replication failed to have an impact on both of the measured sexual behavior outcomes: At the six-month follow-up, BART had no effect on the inconsistency of condom use or the frequency of sex.[REF]
Despite the ineffective replication, the evaluators report that their program “appears to have been implemented with reasonable fidelity” to the BART model.[REF] Thus, poor implementation of the model cannot be used as an excuse for the replication’s ineffectiveness.
The authors appropriately acknowledge that they were attempting to replicate the beneficial impact of a single study published over 20 years ago that may be no longer relevant to today’s youth.[REF] They elaborate that “[i]t is conceivable that any historical change in adolescents’ social, normative, educational, and informational environments now as compared with then could help explain differences in findings.”[REF] Not only was the BART replication based on high-quality evidence that found more failure than success, but the grant award was based on an outdated study.
Children’s Aid Society (CAS)–Carrera Program.
Prior Evaluation. The OAH classified the Carrera program as “evidenced-based” based on a single-site “high-quality” randomized experiment published in 2002.[REF] The 2002 study assessed the effectiveness of a three-year multifaceted intervention that served primarily black and Hispanic teens ages 13 to 15. The multifaceted intervention included job-related training, academic assistance, sex education, art instruction, sports activities, and mental health and health care services.[REF] At the time of the three-year follow-up, 484 intervention and control group members were assessed on several sexual and reproduction outcomes.
Overall, the intervention and control group members had self-reported rates of 63 percent and 72 percent for ever having had sex, respectively—a statistically significant difference of 9 percent.[REF] However, this beneficial effect was primarily the result of females reporting statistically lower occurrences of ever having had sex, compared to no effect for males.
Generally, the program failed to affect reported use of condoms and hormonal methods during most recent intercourse.[REF] This inconclusive finding was the result of the different responses by gender. For females, the intervention and control group members had self-reported rates of using condoms and hormonal methods of 36 percent and 20 percent, respectively—a statistically significant difference of 16 percent. However, the program had a harmful impact for males, with reported outcomes of 9 percent and 20 percent for male intervention and control group members, respectively—a statistically significant harmful impact of 11 percent. When the usage of only condoms was assessed, the intervention failed to affect reported use, even when the outcomes were reported by gender.
The intervention reduced self-reported incidences of becoming pregnant or causing a pregnancy with reported rates of 10 percent and 17 percent for the intervention and control groups, respectively.[REF] The impact was a statistically significant difference of 7 percent. However, this effect was driven entirely by the impact on females. Similarly, the intervention had no overall impact on reports of giving birth or becoming a father. However, when the sample itself was limited to females, 3 percent of the intervention group reported giving birth, compared to 10 percent for the control group—a statistically significant difference of 7 percent. The program had no effect on male self-reports of becoming fathers.
TPP Tier I Replication. The OAH funded two evaluations of the Carrera program that have been released to the public—an experimental evaluation and a quasi-experimental evaluation. The experimental evaluation assessed the impact of the program using the random assignment of 600 students ages 13 to 15 from three schools in the Englewood neighborhood of Chicago.[REF] The Chicago replication was implemented over four years.
There was no evidence that the replication affected any of the measures of sexual activity after four years of programing.[REF] As detailed in Table 1, this replication produced no statistically significant effects on any of the six sexual behavior outcomes. Specifically, the random assignment replication failed to have statistically measurable effects on self-reports of ever having sex and sexual intercourse without contraception.[REF] Further, the replication failed to affect any of these outcomes when analyzed by gender.[REF]
The evaluators report that their program “was not delivered with fidelity, due in large part to the instability of the Chicago Public School (CPS) system.”[REF] For example, only 12 percent of the intervention group attended at least 75 percent of the scheduled sessions. This issue may reflect the failure of the program administrators in getting students interested in participating in the provided services.
The less scientifically rigorous quasi-experimental evaluation attempted to replicate the Carrera program in rural, urban, and “micropolitan” (population of at least 10,000 and less than 50,000) communities in Georgia.[REF] Due to the quasi-experimental design, this study is not summarized in Table 1. The intervention group consisted of youth participating in the Carrera services provided by three community-based organizations, while the comparison group consisted of youth participating in three Boys and Girls Clubs. Each of the rural, urban, and micropolitan locations were represented with an intervention and comparison group site. The initial sample size was 400 adolescents, but dwindled to 204 by the time of the three-year follow-up.
The evaluators reported that the “Carrera Model was implemented with fidelity and quality, particularly with program components and staffing: however, attendance was a challenge.”[REF] Over the course of the three-year intervention, intervention group members increasingly dropped out of the program.
The intervention and control group members were assessed over the course of three years on measures of ever having had sex, and sex without a condom or other birth control. In each of these annual assessments, this replication had no statistically measurable impacts on the outcomes.[REF] Further, no effect occurred when these outcomes were assessed by gender in year three.
¡Cuídate!
Prior Evaluation. The OAH categorizes the ¡Cuídate! program as an evidenced-based model due to a single “high quality” randomized experiment published in 2006.[REF] The OAH also reviewed two other studies that did not meet its criteria for an evidence-based classification because program impacts were not assessed.[REF]
For the highly rated study, 553 Hispanic adolescents in Philadelphia with an average age of nearly 15 were randomly assigned to the ¡Cuídate! program—an HIV prevention program that is an adaption of Be Proud! Be Responsible!—and to a health promotion program that served as the control group.[REF] Over the three-month, six-month, and 12-month follow-ups, the evaluation found that participation in ¡Cuídate! was associated with declines in self-reported sexual intercourse and number of sexual partners, and an increase in consistent use of condoms.[REF] However, there was no effect for the outcomes of condom use at last time of sex and the proportion of days of unprotected sex.[REF] Thus, ¡Cuídate! had beneficial effects on only four of seven outcomes.
TPP Tier I Replication. In an attempt at replication, the OAH funded a large-scale multi-site replication of ¡Cuídate! in a small city in southern California, in Phoenix, and in Boston.[REF] This replication attempt is crucial to the potential of evidence-based policymaking because the “study was designed to address important research and policy questions about the effectiveness of an evidence-based program taken to scale and replicated with different populations and in different settings.”[REF] The rigorous evaluation randomly allocated 2,169 adolescents, primarily Hispanic, to the intervention and control groups.[REF] Outcomes were assessed at the six-month follow-up.
For the entire sample, nine outcomes were assessed.[REF] As summarized in Table 1, ¡Cuídate! had no statistically meaningful effect on any of the outcomes. For sexual behavior, the program had no effect on ever being sexually active, sexually active within the past 90 days, sexual intercourse in the past 90 days, oral sex in the past 90 days, or anal sex in the past 90 days. For sexual risk within past 90 days, the program had no effect on sexual intercourse without birth control, sexual intercourse without a condom, oral sex without a condom, or anal sex without a condom.
When effectiveness was assessed by subgroups, several harmful effects were found. For teens who were sexually active at the beginning of the study, intervention group members were 7 percentage points more likely to report having recently had sexual intercourse than similar teens in the control group.[REF] White teens participating in the Hispanic-focused program were about 9 percentage points more likely to report having recently had oral sex and oral sex without a condom, than similar teens in the control group. For Hispanic and black teens, the program had no effect on all outcomes.
According to the authors, “Each of the grantees successfully delivered the program with fidelity (adherence to its core elements and without modifications that threatened those core elements).”[REF] Thus, the failure of this replication cannot be blamed on a lack of implementation fidelity. Further, this replication provides more evidence that scaling up “evidence-based” models is unlikely to produce successful results.
It’s Your Game: Keep It Real
Prior Evaluation. Initially, the OAH categorized the It’s Your Game: Keep It Real (IYG) program as an evidenced-based model based on a few “moderate quality” randomized experiments.[REF] A 2010 study randomly assigned 10 middle schools from a large urban school district in Texas to intervention and control conditions.[REF] The study suffered from high attrition, so the OAH gave the study a “moderate quality” rating.[REF] The IYG curriculum consists of multiple group-based classroom lessons during the seventh and eighth grades.
The sexual activities of students were assessed during the ninth grade. Students attending the intervention schools were statistically less likely to report initiating sex as well as engaging in oral or anal sex.[REF] For example, 23.4 percent and 29.9 percent of the students attending the intervention and control school, respectively, reported initiating sexual activities by the ninth grade. After adjusting for the background characteristics of the students, members of the control group were 29 percent more likely to initiate sexual activities than their peers in the intervention group. However, IYG had no statistically measurable effect on participants engaging in vaginal sex. Overall, 22.3 percent and 26.9 percent of the intervention and control groups self-reported engaging in vaginal sex, respectively—a statistically insignificant difference.
Another pair of random-assignment evaluations of IYG published in 2012 and 2014 were classified as “moderate” in scientific rigor based on high attrition problems.[REF] The 2012 study assessed the effectiveness of IYG in 15 urban middle schools.[REF] More than 1,200 predominately minority seventh-grade students were followed until the ninth grade. The 15 schools were randomly assigned to a risk-avoidance (RA) program that fulfilled federal abstinence education guidelines, a risk-reduction (RR) program that stressed abstinence along with condom usage for those deciding against abstinence (abstinence-plus), and a control group.
When the RA group was compared to their peers in the control group, RA had no effect on self-reports of any sexual initiation, oral sex, vaginal sex, or anal sex.[REF] However, the RA students were 30 percent less likely to engage in unprotected vaginal sex than their peers in the control group. On the contrary, the RA students were 69 percent more likely to have two or more vaginal sex partners than one or no vaginal sex partners, than their peers in the control group.
When the RR group was compared to the peer control group, RR had mixed effects on self-reports of any sexual initiation, oral sex, vaginal sex, or anal sex.[REF] For the initiation of any sexual activity, students in the RR group were 35 percent less likely to engage in such activities than their peers in the control group. While RR had no effect on the likelihood of engaging in oral and anal sex, the program was associated with a 36 percent decrease in the likelihood of having vaginal sex. Further, students with access to RR instruction were 33 percent less likely to engage in unprotected vaginal sex than members of the control group.
While the 2012 study had problems with attrition, the authors also warned that “baseline imbalances in demographics and prevalence of sexual behavior between study conditions may have biased outcomes away from the null hypothesis.”[REF] For example, students in the control schools had higher rates of previously engaging in sexual activity than students in the RA and RR schools.[REF] Thus, the underlying biases in the study may cause the effects—beneficial and harmful—to be overstated. This bias may be the result of cluster randomization used by the evaluators.
In a follow-up to the 2012 study, the 2014 study updates the findings for the 10th grade.[REF] Again, the 2014 study suffers from the same attrition and selection bias that afflicted the 2012 study. By the 10th grade, students in the RA and RR schools were just as likely to report engaging in any sexual activity, oral sex, or vaginal sex.[REF] However, students in the RA and RR schools were 36 percent and 35 percent less likely to report engaging in anal sex than their peers in the control schools, respectively. Students in the RA schools were 39 percent less likely to have unprotected vaginal intercourse, while there was no effect for students in the RR schools. In contrast, the RA and RR groups were 180 percent and 114 percent more likely to have two or more vaginal sex partners than one or no vaginal sex partners, respectively, compared to their peers in the control group.
TPP Tier I Replication. In an attempt at replication, the OAH funded two large-scale replications of IYG in two locations in South Carolina and Texas.[REF] Published in 2016, the South Carolina multi-site study randomly assigned 24 rural middle schools across the state, representing 3,143 students, to provide IYG services or the usual non-evidence-based sex education programming. Except for age, students in the IYG and control schools did not statistically differ in baseline characteristics.[REF] On average, students in the control schools were 0.1 years older.
To assess the effectiveness of IYG, the self-reported behavioral outcomes were assessed in the eighth and ninth grades. As presented in Table 1, the evaluation found that IYG had one harmful impact and four statistically insignificant impacts. Students in the IYG schools were no more, and no less, likely to initiate vaginal intercourse by the end of the eighth grade than students in the control schools.[REF] By the end of the ninth grade, however, the students in the IYG schools were 27 percent more likely to engage in vaginal intercourse than similar peers in the control schools. This harmful impact, when translated into an effect size (Cohen’s d) is 0.10, which is extremely small.[REF] Interpreting this harmful effect, the authors write that the “usual programming outperformed IYG, although the magnitude of the difference was small.”[REF] Additionally, within the last three months at the time of the ninth-grade follow-up, the IYG replication failed to affect incidences of vaginal intercourse, sex without effective birth control, and sex without the use of condoms.[REF]
Could a failure in faithfully implementing the IYG model have led to the replication’s failure? The authors do not seem to think so: “Fidelity and quality of implementation by IYG facilitators was high, as was students’ exposure to the curriculum.”[REF]
The authors raise two important issues that may explain why scaling up and replication may not work. First, the South Carolina replication “was an effectiveness trial that used classroom teachers for implementation rather than an efficacy trial more tightly controlled by the original researchers; existing literature suggested effectiveness trials often yield smaller effects than efficacy trials.”[REF] Efficacy trials test whether a social program is effective under optimal conditions, while effectiveness trials test the effectiveness of social programs delivered in real-world conditions.[REF] Second, the authors acknowledge that replicating supposedly effective models in different settings and with dissimilar demographic groups does not mean that the same results should be expected.
The single-site replication of the IYG in Houston evaluation randomly assigned 10 middle schools to the IYG group, and 10 middle schools to the control group.[REF] The control group schools implemented regular school-based health education programming. The baseline sample consisted of 2,403 students.[REF] The final sample of students for assessing program impact was limited to students who reported having had no vaginal or oral sex at baseline.[REF]
Students in the IYG and control schools did not statistically differ in demographic characteristics.[REF] However, there was an important difference between the intervention and control groups at baseline. The school-level rate of seventh-graders reporting ever having had sex was 12.14 percent in the IYG schools, and 7.02 percent in the control schools—a statistically significant difference of 5.12 percent.[REF] This difference may reflect different cultures and underlying characteristics in the schools that may bias the impact estimates. This bias is another reason why cluster randomization does not have the same scientific rigor as individual randomization.
Despite being implemented in an urban setting like the original evaluations of IYG, the Houston replication failed to produce any impacts on three sexual behavior outcomes during the follow-up in the ninth grade.[REF] (See Table 1.) Students in the IYG schools did not differ on self-reported measures of the initiation of vaginal or oral sex.
Similar to the authors of the South Carolina replication, the authors of the Houston replication offer the use of school teachers for IYG curriculum instruction, instead of outside experts, as a possible explanation for the replication’s failure.[REF] Program models are less likely to succeed when implemented under real-world conditions. Further, the authors did not provide evidence that the IYG model was poorly implemented in Houston.
Promoting Health Among Teens! Abstinence-Only Intervention
Prior Evaluation. Based on small, single-site “high quality” randomized evaluation, the OAH classified Promoting Health Among Teens! Abstinence-Only Intervention as an “evidence-based” model.[REF] In all, 662 black sixth-grade and seventh-grade students from four public middle schools in a city in the Northeast were randomly assigned to five groups that received different educational services:
- Abstinence-only intervention;
- Safer sex-only intervention;
- Comprehensive intervention (short duration);
- Comprehensive intervention (long duration); or
- Health-promotion control intervention.
The abstinence-only intervention offered participants eight hours of instruction on the risks of sexual activity and benefits of abstinence, while the safer sex-only intervention offered similar instruction on the risks of sexual activity, but differed from the abstinence-only instruction by encouraging the use of condoms.[REF] The comprehensive interventions offered eight hours and 12 hours of instruction on the risk of sexual activity and encouraged abstinence. However, this intervention offered instruction on condom usage to students deciding to have sex.[REF] The health-promotion control intervention “focused on behaviors associated with risk of heart disease, hypertension, stroke, diabetes, and certain cancers. It was designed to increase knowledge and motivation regarding healthful dietary practices, aerobic exercise, and breast and testicular self-examination, and to discourage cigarette smoking.”[REF]
Outcomes were assessed over a 24-month period. Students in the abstinence-only intervention had a 33.5 percent probability of ever having sexual intercourse, compared to 48.5 percent for similar peers in the control group.[REF] The risk ratio for this effect is 0.67, which means that members of the abstinence-only intervention group were 33 percent less likely to engage in sexual intercourse, compared to similar students in the control group.[REF] Members of the abstinence-only intervention were also slightly less likely to engage in sexual intercourse within the last three months.[REF] The risk ratio for this outcome was 0.94, which translates into a decrease of 6 percent. As for the other comparisons, the “safer sex and comprehensive interventions did not differ from the control group in sexual initiation.”[REF]
The authors of the evaluation add context to the findings by cautioning that the “results of this trial should not be taken to mean that all abstinence-only interventions are efficacious.”[REF] Further, and perhaps most important for federal policy, “[t]his trial tested a theory-based abstinence-only intervention that would not have met federal criteria for abstinence programs.”[REF]
TPP Tier I Replication. The OAH awarded a grant to replicate the Promoting Health Among Teens! Abstinence-Only Intervention in Yonkers, New York.[REF] The single-site evaluation randomly assigned more than 1,300 sixth-grade and seventh-grade students to the intervention and control groups in eight middle schools in sections of the city with the highest occurrences of births to teens. Members of the control group were offered the Promoting Health Among Teens! Health Intervention that offered educational programming regarding the benefits of exercise and healthy eating habits.
Baseline characteristics of the treatment and control group did not differ at the time of the 12-month follow-up.[REF] As summarized in Table 1, the replication failed to affect all three of the sexual behavior outcomes. The intervention failed to yield statistically significant results on the self-reported outcome of ever having had sex during the three-month, six-month, and 12-month follow-ups.[REF] For example, 1.3 percent and 2.1 percent of the intervention and control group self-reported ever having had sex, respectively, at the 12-month follow-up—a statistically insignificant difference of 0.8 percent.[REF]
The failure of the replication cannot be blamed on poor implementation because “the results of this evaluation also suggest that implementation fidelity is a necessary but not sufficient condition for attaining successful replication. This replication attained a high level of fidelity and yet failed to reproduce the original findings.”[REF] The authors also caution against the assumption that replicating program models based on outdated studies will produce the same results, Further,
[i]t is perhaps the case that evidenced-based interventions from a decade or so ago may lose their relevancy in more contemporary times. Human behavior is dynamic and subject to broader changes and influences from a myriad of sources. Thus, when consideration is being given to testing the effectiveness of an intervention where there has been some time lag, situating that intervention in the present reality and adapting it to meet this reality may be one of the decisions potential implementers need to make.[REF]
Reducing the Risk
Prior Evaluation. Based on several experimental and quasi-experimental studies rated as “moderate quality” to “low quality” in scientific rigor, the OAH classified the Reducing the Risk program as an evidence-based model.[REF] All of these studies earned rankings lower than “high quality” due to the methodological shortcomings of these studies, so the results need to be interpreted with great skepticism.[REF] Further, two studies with moderate ratings did not provide consistent evidence of effectiveness.[REF]
A 2008 cluster random assignment study of Reducing the Risk that suffered from high attrition study was classified by the OAH as having no impact on sexual outcomes.[REF] The study was rated as “moderate quality” in scientific rigor by the OAH. The evaluators randomly assigned 17 schools, consisting of 1,944 students, to three curricula: Reducing the Risk, modified version of Reducing the Risk, and the standard curriculum. The schools were located in Cleveland, Ohio, and Louisville, Kentucky. Reducing the Risk is a curriculum
designed to enhance students’ skills to resist unprotected sex by modeling those skills and then providing students opportunities for practice. The curriculum emphasizes that youth should avoid unprotected intercourse; that the best way to do this is to abstain from sex; and that if they do not abstain from sex, they should use contraceptives (especially condoms) to guard against pregnancy and STDs, especially HIV.[REF]
The modified version of Reducing the Risk was “specifically designed for high sensation-seeking and impulsive students” and the standard curriculum offered in the schools served as the control.[REF] All of the services provided had the goal of preventing pregnancy and HIV. Students were assessed from the beginning of the ninth grade and the end of the 10th grade.
Attrition rates at the three-month and six-month follow-ups were statistically different for the three groups.[REF] Further, students who reported being more sexually experienced were less likely to complete the follow-up surveys. Only 52 percent of the original sample completed the 12-month and 18-month follow-up surveys. Not only did the 2008 evaluation suffer from attrition, but the three groups of students were not statistically equivalent on gender, race, or educational aspirations.[REF] This problem means that the individual students are not equivalent on these factors—a problem not uncommon with cluster randomization.
Overall, participation in Reducing the Risk or the modified version had no effect on initiating sexual intercourse, compared to students in the standard curriculum.[REF] However, when the samples of both Reducing the Risk interventions are combined, students that received the standard curriculum were less likely to engage in sexual intercourse.
A quasi-experiment that resulted in two publications published in 1991 and 1992 was rated as “moderate quality” in scientific rigor by the OAH.[REF] The 1991 study tried to assess the effect of Reducing the Risk by non-randomly allocating more than 1,000 high school students from 13 California schools to intervention and comparison groups.[REF] Only 758 students responded to the 18-month follow-up survey.
Questionably, the OAH assigned the 1991 study a “moderate quality” scientific-rigor rating, even though the quasi-experiment only tested the statistical differences in outcomes between the intervention and comparison groups without controlling for any variables that could influence the outcomes.[REF] At the six-month follow-up, the difference between the self-reported initiation of intercourse for the intervention and comparison groups did not differ.[REF] At the 18-month follow-up, the intervention group had a statistically significant lower rate of self-reported intercourse.
Interestingly, the authors performed a logistic regression which would presumably control for some factors that could influence self-reported outcomes.[REF] The presumably more rigorous logistic regression found that Reducing the Risk failed to affect the initiation of sexual intercourse.
When the outcome of unprotected intercourse was estimated for all of the students in the study, Reducing the Risk failed to affect this outcome.[REF] Further, Reducing the Risk had no effect on whether female students reported becoming pregnant or male students reported getting a girl pregnant.
The 1992 study of the same sample of students reports findings only from the six-month follow-up for the same evaluation.[REF] It used the same weak methodology of the 1991 study. The 1992 study found no differences in rates of sexual intercourse and pregnancy between the intervention and comparison groups at the six-month follow-up.[REF]
After Reducing the Risk was designated an “evidence-based” model by the OAH, a multi-site evaluation of over 700 adolescents drawn from high schools and community youth groups was published in 2014.[REF] The study was originally intended to use random assignment to assess the impact of Reducing the Risk and a revised Reducing the Risk curriculum (RTR+) in three states (Arizona, New York, and Texas). After the initial random assignment, however, the evaluators non-randomly reassigned some of the sample to intervention and control groups, so the study is not a true randomized experiment.[REF] The OAH classified the study as moderate in scientific rigor and concluded that the program has no effect on relevant outcomes.[REF]
Self-reported sexual activities of the sample were followed up at three months, six months, and 12 months.[REF] There were no differences between the control group and the Reducing the Risk group in the likelihood of sexual initiation during all three of the follow-ups.[REF] The pattern of ineffectiveness was almost similar for the revised Reducing the Risk curriculum. The revised curriculum had no effect on sexual initiation for the first two follow-up periods, while members of this intervention group were less likely to engage in sexual activity at the 12-month follow-up.
The number of self-reported sexual partners and number of unprotected sexual acts were also assessed. The regular Reducing the Risk curriculum did not have statistically meaningful effects on either outcome.[REF] While the revised Reducing the Risk curriculum was associated with a decrease in the number of sexual partners, the intervention had no effect on unprotected sex acts. Thus, both of these “evidence-based” interventions failed to affect the majority of outcomes.
TPP Tier I Replication. The OAH awarded grants to fund two replications of Reducing the Risk.[REF] The first single-site replication study used cluster randomization to assess the impact of Reducing the Risk and another intervention, Love Notes, in Louisville, Kentucky.[REF] At the time of the award for this Tier I grants, Love Notes was not classified as an evidence-based model. According to the authors, Love Notes “embeds pregnancy and disease prevention messages in a curriculum that emphasizes the importance of forming healthy relationships and avoiding intimate partner control or violence for individuals to reach their life goals.”[REF] The control curriculum was The Power of We (POW) curriculum—a program for teaching adolescents to “learn more about assets in their neighborhoods and ways to bring about positive change.”[REF] However, “POW did not include any mention of individual planning, self-esteem, sexual health, healthy relationships, or intimate partner violence, and thus had zero overlap with content in either” Reduce the Risk or in Love Notes.[REF] The interventions implemented in Louisville were performed by highly trained academics, so this replication can be considered an efficacy evaluation as the programs were implemented under optimal conditions.
Students ages 14 to 19 who were thought to be of high risk for pregnancy and were participating in a community-based organization were recruited for participation in the study.[REF] Once the teens were randomly assigned to clusters, the clusters were randomly assigned to three conditions.[REF] At baseline, 1,365 teens were involved in the evaluation. Because the technique does not randomly assign individuals, cluster randomization may not yield equivalent groups.[REF] Members of the Reducing the Risk and Love Notes groups were slightly more likely to be non-Hispanic blacks than members of the control group.[REF]
Of the eight sexual outcomes measured, Reducing the Risk had no effect on half, while the intervention had beneficial impacts on the other half. (See Table 1.) At the time of the three-month follow-up, Reducing the Risk had no effect on two of the four outcomes assessed.[REF] Compared to control group teens, those in the Reducing the Risk group were no more or less likely to report having sex without a condom, or ever having sex. However, teens in this intervention group were less likely to report having sex without any type of birth control and had fewer reports of several sexual partners.
The results for Reducing the Risk at the six-month follow-up are similar.[REF] The intervention had no impact on condom usage and ever having sex, while the program was associated with decreased self-reports of having sex without any form of birth control and the number of sexual partners.
At the time of the three-month follow-up, Love Notes had no effect on any of the four outcomes assessed.[REF] Compared to the control group, those in the Loves Notes group were no more or less likely to use condoms, use any form of birth control, or have sex. The number of sex partners of this intervention group was not statistically different from what was reported by the control group. By the time of the six-month follow-up, however, the results for Love Notes changed completely—the intervention was associated with beneficial outcomes on all four measures.[REF]
In regards to Love Notes, the evaluators caution that a “replication of these results is needed to increase the strength of the evidence for the intervention.”[REF] For the OAH and others to label Love Notes an “evidence-based” model would be premature because the results are based on a single-site evaluation that was not implemented under real-world conditions.
A more relevant evaluation for policymakers is the large-scale, multi-site replication of Reducing the Risk in six schools in St. Louis, Missouri, five schools in Austin, Texas, and six schools in San Diego, California.[REF] Like the other replication evaluation, the evaluators of this study randomly assigned classes to intervention and control groups. The control classrooms received the “business as usual” curriculum. In all three sites, the intervention was implemented in public school classrooms that ranged from the eighth to tenth grades. At the start of the study, 3,314 students in 150 classrooms participated in the study.[REF] At the time of the 12-month follow-up, 2,689 (81 percent) of the original sample completed the self-reported survey.
According to the evaluators, the intervention “was well implemented across the 3 replication sites” and the “program was delivered with fidelity.”[REF] Despite the successful implementation of the intervention, members of the intervention classrooms in the three sites did not differ on seven outcomes of sexual behavior and risk at the 12-month follow-up, in contrast to similar members in the control classrooms.[REF] For sexual behavior, Reducing the Risk failed to affect being “ever sexually active,” “currently sexually active,” having “sexual intercourse,” and having “oral sex.” Further, the intervention had no effect on sexual intercourse without any birth control, sexual intercourse without a condom, or oral sex without a condom.
When the results were analyzed by the three sites, Reducing the Risk failed to have any impact on all seven measures in the Austin and San Diego sites.[REF] In the St. Louis site, the intervention failed to affect six of the seven outcomes. The only measure that had a statistically significant effect was the self-reported decrease in engaging in sexual intercourse.
The findings of this replication provide caution for expecting similar results of “evidence-based” models taken to scale. As the authors acknowledge, “As an examination of the effectiveness of evidence-based programs and what happens when they are taken to scale, replicated with different populations, and offered in different settings, this study provides important information on the effectiveness of Reducing the Risk.”[REF] Further, the “evidence for the effectiveness of this program is from a single quasi-experimental study completed 25 years ago in rural and urban areas of northern California with primarily White high school students.”[REF] Thus, what worked in one setting did not work in other settings.
Safer Sex Intervention
Prior Evaluation. The OAH assigned the Safer Sex Intervention (SSI) model an evidenced-based classification based on a single-site “moderate quality” randomized experiment published in 2001.[REF] Suffering from high attrition, the 2001 study randomly assigned 60 and 63 youth to the intervention and control group, respectively. The sample of sexually active female participants were less than 24 years old, and were either attending a hospital-based clinic for treatment for cervicitis or were admitted to a hospital for management of pelvic inflammatory disease. During patient visitations, participants were asked about their sexual activities in one-month, six-month, and 12-month follow-ups. Only 33 percent of participants attended all follow-up visits.
Dealing with a population already infected with a sexually transmitted disease (STD), the SSI curriculum imparted information on how to change sexual behavior to reduce risks that also involved individualized sessions tailored to the participants.[REF] Members of the control group received standard STD education.
The following seven outcomes were assessed during each of the three follow-up visits:
- Condom usage with last sexual encounter;
- Currently have a main sexual partner;
- Frequency of condom use with main partner in last five sexual encounters;
- Consistent use of condoms (“Every time”) with main partner;
- Another partner in the last six months;
- Frequency of condom use with another partner in last five sexual encounters; and
- Consistent use of condoms (“Every time”) with another partner.[REF]
At the one-month follow-up, SSI failed to affect all seven of the outcome measures.[REF] At the six-month follow-up, participation in the intervention had no statistically measurable effect on six of seven outcomes. Members of the intervention group were less likely to report sexual partners in addition to their main partner than similar members in the control group. The intervention failed to have any statistically significant effect on all seven outcomes at the 12-month follow-up. Thus, of a total of 21 outcomes, the program had only one (4.8 percent) statistically significant outcome.
TPP Tier I Replication. The OAH awarded grants to fund two replications of SSI.[REF] The first replication was a small single-site evaluation that assessed the impact of SSI implemented in New Orleans, Louisiana.[REF] Girls ages 14 to 19 were referred by clinicians, and clinic staff were asked to participate in the study. Individuals were randomly assigned to intervention (SSI) and control groups. The results are based on 268 participants with 133 in the SSI group and 135 in the control group.
For all three sexual behavior outcomes, the intervention failed to have statistically measurable impacts. (See Table 1.) According to the evaluators, the primary outcome for judging the effectiveness of SSI was the inconsistency of condom usage at the six-month follow-up.[REF] According to the author, the “Safer Sex intervention had no significant effect on participants’ inconsistency of condom use.”[REF] Fifty percent of the SSI group reported inconsistent use, compared to 46 percent for the control group—a statistically insignificant difference of 4 percent.[REF]
The same pattern of ineffectiveness occurred with the secondary outcomes. SSI had no statistically meaningful impact on the inconsistency of contraceptive use and the frequency of sex.[REF] Thus, SSI, as implemented in New Orleans, failed to affect all three outcome measures.
The second replication evaluation used random assignment to assess the impact of SSI in multiple sites.[REF] More than 1,200 female adolescents attending 38 clinics in Minnesota, Tennessee, and Florida were randomly assigned to SSI and a control group. Control group members received the standard, less-intensive care provided by the clinics. Thus, this replication attempted to scale-up SSI.
As summarized in Table 1, the replication failed to affect nine of 10 sexual behavior outcomes. At the nine-month follow-up, 86 percent of the study participants completed self-reported surveys.[REF] According to the evaluators, the main indicators of effectiveness was sexual activity in the past 90 days, and sexual intercourse without birth control in the past 90 days.[REF] SSI failed to affect whether participants were sexually active, but did decrease self-reported sexual intercourse without birth control.[REF] For this measure, 22.05 percent of the SSI and 27.82 percent of the control group reported having sexual intercourse without using birth control—a statistically significant difference. According to the evaluators
SSI had no impact on any other measures of sexual activity. The program was not effective in reducing sexual intercourse, oral sex, or anal sex in the past 90 days. It did not affect rates of condom use during sexual intercourse, oral sex, or anal sex, nor did it affect the likelihood of having sexual intercourse with more than 1 partner or more than 5 partners in one’s lifetime.[REF]
Seventeen Days
Prior Evaluation. Similar to other classifications, the OAH assigned the Seventeen Days (formerly What Could You Do?) model an evidenced-based classification based on a single-site “high quality” randomized experiment published in 2004.[REF] Seventeen Days employs an interactive video intervention that attempts to increase the aptitude of participants in making less-risky sexual decisions. In the area of Pittsburgh, Pennsylvania, 300 urban adolescent girls were randomly assigned to the Seventeen Days intervention group and two control groups. The first control group used books to offer the same information that Seventeen Days delivered in interactive videos. The second control group was provided commercially available brochures covering the same topics.
The outcomes consisted of self-reported questions regarding sexual behavior and the acquisition of STDs.[REF] More important, medical tests for chlamydia trachomatis were administered. In the realm of sex education, outcomes are almost exclusively based on self-reported data that can be susceptible to false or misleading answers. For this reason, the use of a medical test generates more reliable data than self-reported measures. This is an important advancement in the evaluation literature.
Despite using random assignment, the predispositions of the intervention group were statistically different from members of the control groups on a key factor that may have substantially affected the outcomes.[REF] Woman assigned to the Seventeen Days group were more likely to be sexually abstinent than members of both control groups. Unsurprisingly, the intervention group was more likely to report being abstinent during the three-month and six-month follow-ups.[REF]
Participation in Seventeen Days had no effect on condom use at the three-month and six-month follow-ups.[REF] However, those in the intervention group reported fewer condom failures than their counterparts in the control groups. As for STDs, the intervention group self-reported lower rates of acquiring any type of STD. Except for chlamydia, the number of participants reporting specific types of other STD infections were too small to conduct valid statistical tests.
According to self-reports, members of the Seventeen Days group were significantly less likely to have chlamydia than their counterparts. However, this result demonstrates the unreliability of self-reported data, because the results of the chlamydia medical test found that Seventeen Days failed to yield statistically significant results. Thus, the results of self-reported outcomes need to be taken with a healthy dose of skepticism.
TPP Tier I Replication. The OAH attempted to replicate and scale up Seventeen Days in Ohio, Pennsylvania, and West Virginia.[REF] The large-scale, multi-site evaluation randomly assigned more than 1,300 sexually active girls ages 14 to 19 who attended 20 clinics in the three states to intervention and control groups.
The samples for the three-month and six-month follow-ups had 52 percent and 43 percent response rates, respectively, suggesting that attrition was a problem.[REF] However, the evaluators report that there was no difference in attrition between the intervention and control groups. The resulting samples for the follow-ups did not differ in baseline characteristics, despite attrition.[REF]
Of the six sexual behavior outcomes, Seventeen Days failed to affect all. (See Table 1.) The evaluators found “no evidence that viewing Seventeen Days [the video] impacted engaging in safe sexual behavior compared to the comparison group.”[REF] At the three-month follow-up, the intervention failed to have any effect on sexual behaviors or abstinence.[REF] At the six-month follow-up, the results were similar. The intervention failed to affect any sexual behavior or abstinence.[REF]
Notably, the evaluators did not completely rely on self-reported outcomes. In addition to pregnancy tests, the evaluators tested for chlamydia and gonorrhea. At the time of the six-month follow-up, participation in Seventeen Days failed to effect positive test results for pregnancy and STD infection.[REF]
Teen Outreach Program
Prior Evaluation. The OAH assigned the Teen Outreach Program (TOP) model an “evidenced-based” classification based on a single-site, “high quality” randomized experiment published in 1997, and a 2001 quasi-experiment with a “low quality” ranking.[REF] The 2001 quasi-experiment failed to establish that members of the intervention and comparison groups were similar enough to ensure that the impact estimates were scientifically valid, so the results are not discussed.[REF] As detailed later, the 1997 study had similar flaws.
TOP has the goal of reducing teenage pregnancy, academic failure, and school suspension.[REF] For the purposes of TPP, the OAH only considered the teen-pregnancy-related outcomes for assessing whether to classify the model as evidence-based. The main emphasis of TOP “is to engage young people in a high level of structured, volunteer community service that is closely linked to class-room-based discussions of future life options, such as those surrounding future career and relationship decisions.”[REF]
The 1997 multi-site study assessed the impact of TOP in 25 sites nationwide using a sample of 695 high school students.[REF] The majority of the sample was randomly assigned on the level of the individual, however, it was not possible to use individual random assignment for all the sites. In these cases, classrooms were randomly assigned. The sample consisted of students in the ninth to 12th grades. Consequently, the study is not a true individual-level randomized experiment.
Despite the mixed method of random assignment (or perhaps because of it), the intervention and control groups were not equivalent on key factors at the beginning of the study. Members of the control group had statistically higher incidents of prior course failure, school suspension, and pregnancy.[REF] Therefore, the classification of this study as “high” in scientific rigor is extremely questionable.
Unfortunately, the impact of TOP over time is unknown, because the evaluators only assessed outcomes at the time of program exit.[REF] This means that this evaluation cannot inform policymakers about the effectiveness of TOP after students left the program. The evaluators found that the risks of self-reporting a pregnancy were greatly reduced for the TOP group, compared to the risks of the control group.[REF] In fact, the “[r]isk of teen pregnancy was only 41% as large as in the control group.”[REF] Due to the intervention and control groups not being equivalent on key factors that likely affected the outcomes, the results of this evaluation are highly suspect.
TPP Tier I Replication. Through two large-scale, multi-site evaluations, the OAH tried to replicate the TOP model in sites throughout the nation.[REF] Both evaluations used cluster randomization.
The first evaluation assessed the effect of TOP and consisted of an ethnically diverse sample of middle and high school students drawn from varied locations:
- Hennepin County, Minnesota;
- Northwestern states (Idaho, Montana, Oregon, Washington, and Alaska);
- Kansas City, Missouri;
- Nonmetropolitan counties in Florida; and
- Chicago, Illinois.[REF]
In the Northwestern states and Kansas City, the randomization procedure assigned classes to intervention and control groups.[REF] In Chicago and Florida, schools were randomly assigned, while in Hennepin County, teachers were assigned to the groups. In Florida, schools were matched in pairs based on similar characteristics, and the pairs were then randomly allocated to the groups. In all, 17,194 students participated in the study.
The outcomes are based on self-reported data.[REF] Varying across the geographic sites, the follow-up periods ranged from nine to 24 months.[REF] The first outcome assessed whether sexually inexperienced students at baseline ever had sex. The other two outcomes assessed whether the entire sample ever had sex and had sex without contraception.
When the combined impact of the program across all the geographic locations was assessed, the program failed to affect any of the three sexual behavior outcomes. (See Table 1.) When the results were analyzed by geographic locations, the program failed to affect any of the 27 sexual behavior outcomes. In each of the sites, TOP had no effect on sexually inexperienced students ever having sex. Further, TOP failed to affect the self-reported outcomes in each of the geographic locations.[REF]
The evaluators concluded that
[b]ased on data from 5 studies that, together, included more than 17,000 youths in 5 diverse geographic settings, we found little evidence to support the effectiveness of TOP in reducing sexual risk-taking behaviors that should, in turn, reduce adolescent pregnancy. Because most programs identified by the TPP Evidence Review as of 2016 are based on evidence from single studies, the extent to which these programs will be effective in different settings and with different populations over time is a critical question as the evidence base continues to evolve.[REF]
The other evaluation assessed the impact of TOP in Louisiana communities and Rochester, New York.[REF] Using individual-level random assignment, three cohorts consisting of 2,428 Louisiana and 824 Rochester teens were randomly assigned to intervention and control groups. In both locations, TOP failed to delay sexual onset and having sex without birth control at the three-month follow-up.[REF] The cumulative effect of the program implemented in both sites is not presented by the authors. Of the two sexual behavior outcomes for each site, the program failed to affect either of the outcomes. (See Table 1.) The authors conclude that the “results of these 2 community-based trials did not demonstrate that TOP had an immediate impact on sex with no form of effective birth control in the past 3 months, nor did it demonstrate an impact on delay of sexual onset among youths who reported never having had sex at baseline.”[REF]
Lessons Learned
If the evidence-based-policymaking community is serious about funding what works and defunding what does not work, terminating funding for TPP should be an easy decision. A close review of the scientific literature to identify “evidence-based” TPP program models and their replications reveals several lessons for the evidence-based-policymaking community and policymakers.
Weak Evidence, Weak Replication Findings. Some of the studies used to classify the programs as evidence-based had serious flaws. First, inconclusive evidence was used to label program models, such as BART, as “evidence-based.” Since two of three “high quality” experimental evaluations found that BART was ineffective, the program model should not be labeled as “evidence-based.” Additionally, the OAH classified programs as “evidence-based” if they found at least one beneficial outcome. Thus, a program with a single beneficial outcome, and many outcomes of no effect, would be labeled “evidence-based.”
Second, some of the studies had intervention and control groups that were not equivalent on key variables that may have affected the outcomes. Cluster randomization should not be considered to have the same methodological rigor as individual-level randomization. For example, the race and ethnicity composition of the intervention and control groups for Reducing the Risk replications in Louisville, Kentucky, were not equivalent.[REF] In addition, the intervention group for the Houston IYG replication came from schools that were more likely to have students already engaged in sexual activity by the seventh grade than students attending the control group schools. Given these crucial differences on observable variables, the intervention and control groups are very likely to also differ on critical unobserved factors that can influence the impact estimates. Thus, the results of these studies should be taken with great caution.
Single-Instance Fallacy. Just because an evidence-based program appears to have worked in one location does not mean that the program can be effectively implemented on a larger scale (scaled up), in different locations, or with different populations. Proponents of evidence-based policymaking should not automatically assume that pumping taxpayer dollars into programs attempting to replicate previously “successful” findings will yield the same results. Failure is the norm.
The faulty reasoning that drives such failed expansions of social programs is known as the “single-instance fallacy.”[REF] This fallacy means believing that a single-site social program that works in one instance will yield the same results when scaled up, or replicated elsewhere. Additionally, programs thought to be effective based on decades of old research may not be relevant today. What worked in the 1980s or 1990s may not work in 2017. The TPP Tier I replications certainly prove this point.
Compounding the effects of this fallacy, one often does not truly know why a certain program worked in the first place. In particular, the dedication and entrepreneurial enthusiasm of a program’s founder and the quality of original instructors are difficult to quantify or duplicate. The single-instance fallacy, is perhaps, the most overlooked problem when the evidence-based-policymaking community generalizes the results of the scientific literature.
The OAH’s definition that defines a program model as “evidence-based” based on a single evaluation with a single beneficial outcome is faulty. A more meaningful way to deem program models “evidence-based” only occur after they have been found by experimental evaluations to have consistent statistically significant effects that ameliorate the targeted social problem in at least three different settings.[REF] Once a program model has been found to produce meaningful results in multiple settings, the likelihood of its successful replication elsewhere should increase significantly.
Implementation Fidelity No Guarantee for Success. For many of the replication evaluations, the program models were well implemented, so lack of implementation fidelity cannot be to blame for the consistent failure of these programs to change sexual behavior outcomes. In many cases, the evaluator and administrators do not know why the program worked. The exact combination of program ingredients, such as intangible qualities of the staff, that lead to success is often unknown.
Efficacy Trials Do Not Show How Programs Perform in the Real World. A further complicating issue that evidenced-based-policy advocates need to address is the difficulty of replicating and scaling up programs based on efficacy trials. Efficacy trials test whether a social program is effective under optimal conditions and implemented by highly trained professionals.[REF] These programs are carefully monitored to ensure that the participants receive the intended level of treatment. In the real world, program conditions are often much less than optimal.
On the other hand, effectiveness trials test the effectiveness of social programs delivered in real-world conditions.[REF] Under real-world circumstances, staff training and other resource inputs are frequently less than optimal. The distinction between efficacy and effectiveness trials is particularly important when the federal government attempts to replicate and scale up an “evidence-based” model that was deemed effective based on an efficacy trial.
Effectiveness trials provide more valid information about the actual prospects of replicating social programs. For example, the multi-site replication of Reducing the Risk in St. Louis, Austin, and San Diego tells policymakers more about the real potential of the program model than the efficacy trial implemented in Louisville.
Social Programs Can Cause Harm. Evidence-based-policymaking advocates too frequently concentrate on any beneficial, even if only modest, impacts that have been identified. These same advocates need to recognize that social programs can produce harmful impacts, too.[REF] These harmful effects are rarely mentioned by program advocates.
An evaluation used to classify the Carrera program as evidence-based found that males participating in the program were less likely to use condoms than their peers who did not participate in the program.[REF] An evaluation used to label IYG as an evidence-based model found that the RA group members were much more likely to have multiple vaginal sex partners by the ninth grade than their peers in the control group.[REF] By the 10th grade, the RA and RR groups were both more likely to have multiple vaginal sex partners than their peers in the control group.[REF]
The Tier I replications also found harmful impacts. The replication of IYG in South Carolina found that students in the IYG schools were more likely to have sexual intercourse than their peers in the control schools.[REF] The Tier I replication of ¡Cuídate! also had harmful impacts. Among sexually active teens at the beginning of the study, intervention group members became more sexually active.[REF] Further, white teens participating in the ¡Cuídate! were more likely to report having recently had oral sex and oral sex without a condom than similar teens in the control group. Evidence-based-policymaking advocates must not ignore the evidence that social programs sometimes cause harm.
Conclusion
The replications of TPP evidence-based program models demonstrate conclusively that the federal government has a dismal record of replicating social programs thought to be effective. The scientific rigor of the evidence used to identify “evidence-based” teen pregnancy prevention programs funded through TPP Tier I grants is highly flawed. Further, evidence-based-policy advocates mistakenly believe that these grants will be automatically effective because they are replicating previously successful program models.
Overwhelmingly, evaluations of TPP grants replicating “evidence-based” models have been demonstrated to be ineffective. Yet, the evidence-based-policy community is virtually silent on this failure. Clearly, replicating an “evidenced-based” model does not guarantee success. When programs that fail to produce results receive reduced funding or are terminated altogether, and when programs that generate results continue to receive funding, the result is a better allocation of scarce resources. Given the overpowering evidence of TPP ineffectiveness, funding for this program should be terminated.
—David B. Muhlhausen, PhD, is a Research Fellow for Empirical Policy Analysis in the Thomas A. Roe Institute for Economic Policy Studies, of the Institute for Economic Freedom, at The Heritage Foundation.


